What are basic SQL Optimization Tips ?
1)Use views and stored procedures instead of heavy-duty queries.
2)Try to avoid using SQL Server cursors, whenever possible.
3)Try to avoid using the DISTINCT clause, whenever possible.
4)Try to restrict the queries result set by using the WHERE clause.
5)Try to avoid the HAVING clause, whenever possible.
6)Try to restrict the queries result set by returning only the particular columns from the table, not all table's columns.
7)If you need to return the total table's row count, you can use alternativeway instead of SELECT COUNT(*) statement.
8)Try to use constraints instead of triggers, whenever possible.
9)Use table variables instead of temporary tables.
10)Use the select statements with TOP keyword or the SET ROWCOUNT statement, if you need to return only the first n rows.
11)Use the FAST number_rows table hint if you need to quickly return 'number_rows' rows.
Important Database designing rules
Rule 1:- What is the Nature of the application(OLTP or OLAP)?
When you start your database design the first thing to analyze is what is the natureof theapplication you are designing for, is it Transactional or Analytical. You will find many developers by default applying normalization rules without thinking about the nature of the application and then later getting in to performance and customization issues. As said there are 2 kinds of applications transaction based and analytical based,let's understand what these types are.
Transactional: - In this kind of application your end user is more interested in CRUD i.e. Creating, reading, updating and deleting records. The official name for such kind of database is called as OLTP.
Analytical: -In these kinds of applications your end user is more interested in Analysis, reporting, forecasting etc. These kinds of databases have less number of inserts and updates. The main intention here is to fetch and analyze data as fast as possible. The official name for such kind of databases is OLAP.
2)Try to avoid using SQL Server cursors, whenever possible.
3)Try to avoid using the DISTINCT clause, whenever possible.
4)Try to restrict the queries result set by using the WHERE clause.
5)Try to avoid the HAVING clause, whenever possible.
6)Try to restrict the queries result set by returning only the particular columns from the table, not all table's columns.
7)If you need to return the total table's row count, you can use alternativeway instead of SELECT COUNT(*) statement.
8)Try to use constraints instead of triggers, whenever possible.
9)Use table variables instead of temporary tables.
10)Use the select statements with TOP keyword or the SET ROWCOUNT statement, if you need to return only the first n rows.
11)Use the FAST number_rows table hint if you need to quickly return 'number_rows' rows.
Important Database designing rules
Rule 1:- What is the Nature of the application(OLTP or OLAP)?
When you start your database design the first thing to analyze is what is the natureof theapplication you are designing for, is it Transactional or Analytical. You will find many developers by default applying normalization rules without thinking about the nature of the application and then later getting in to performance and customization issues. As said there are 2 kinds of applications transaction based and analytical based,let's understand what these types are.
Transactional: - In this kind of application your end user is more interested in CRUD i.e. Creating, reading, updating and deleting records. The official name for such kind of database is called as OLTP.
Analytical: -In these kinds of applications your end user is more interested in Analysis, reporting, forecasting etc. These kinds of databases have less number of inserts and updates. The main intention here is to fetch and analyze data as fast as possible. The official name for such kind of databases is OLAP.

So in other words if you think insert, updates and deletes are more prominent then go for normalized table design or else create a flat denormalized database structure.
Below is a simple diagram which shows how the names and address in the left hand side is a simple normalized table and by applying denormalized structure how we have created a flat table structure.
Below is a simple diagram which shows how the names and address in the left hand side is a simple normalized table and by applying denormalized structure how we have created a flat table structure.
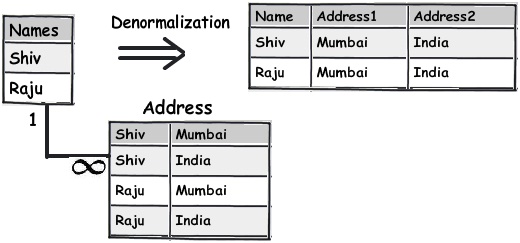
Rule 2:- Break your data in to logical pieces, make life simpler
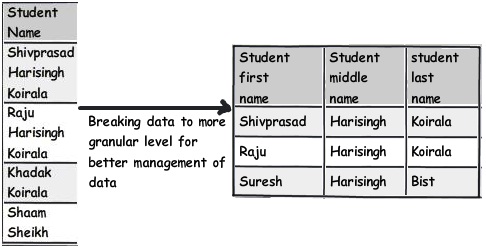
This rule is actually the 1st rule from 1st normal formal. One of the signs of violation of this rule is if your queries are using too many string parsing functions like substring, charindexetc , probably this rule needs to be applied.
For instance you can see the below table which has student names , if you ever want to query student name who is having "Koirala" and not "Harisingh" , you can imagine what kind of query you can end up with.
So the better approach would be to break this field in to further logical pieces so that we can write clean and optimal queries.
This rule is actually the 1st rule from 1st normal formal. One of the signs of violation of this rule is if your queries are using too many string parsing functions like substring, charindexetc , probably this rule needs to be applied.
For instance you can see the below table which has student names , if you ever want to query student name who is having "Koirala" and not "Harisingh" , you can imagine what kind of query you can end up with.
So the better approach would be to break this field in to further logical pieces so that we can write clean and optimal queries.
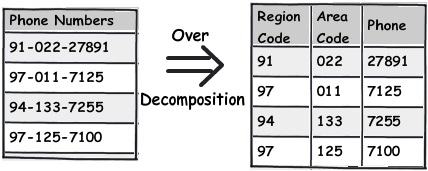
Rule 3:- Do not get overdosed with rule 2
Developers are cute creatures. If you tell them this is the way, they keep doing it; well they overdo it leading to unwanted consequences. This also applies to rule 2 which we just talked above. When you think about decomposing, give a pause and ask yourself is it needed. As said the decomposition should be logical.
For instance you can see the phone number field; it's rare that you will operate on ISD codes of phone number separately(Until your application demands it). So it would be wise decision to just leave it as it can lead to more complications.
Developers are cute creatures. If you tell them this is the way, they keep doing it; well they overdo it leading to unwanted consequences. This also applies to rule 2 which we just talked above. When you think about decomposing, give a pause and ask yourself is it needed. As said the decomposition should be logical.
For instance you can see the phone number field; it's rare that you will operate on ISD codes of phone number separately(Until your application demands it). So it would be wise decision to just leave it as it can lead to more complications.
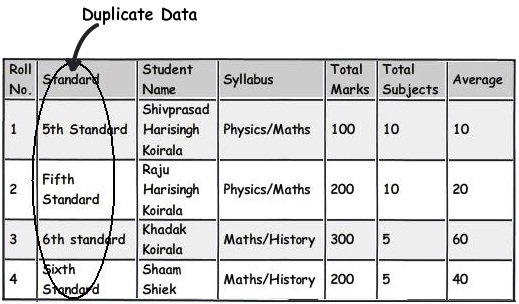
Rule 4:- Treat duplicate non-uniform data as your biggest enemy
Focus and refactor duplicate data. My personal worry about duplicate data is not that it takes hard disk space, but the confusion it creates.
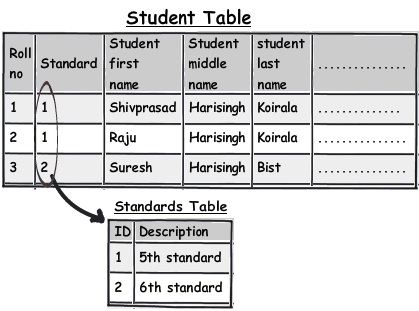
For instance in the below diagram you can see "5th Standard" and "Fifth standard" means the same. Now you can say due to bad data entry or poor validation the data has come in to your system. Now if you ever want toderive a report they would show them as different entities which is very confusing from end user point of view.
Focus and refactor duplicate data. My personal worry about duplicate data is not that it takes hard disk space, but the confusion it creates.
For instance in the below diagram you can see "5th Standard" and "Fifth standard" means the same. Now you can say due to bad data entry or poor validation the data has come in to your system. Now if you ever want toderive a report they would show them as different entities which is very confusing from end user point of view.
One of the solutions would be to move the data in to a different master table altogether and refer then via foreign keys. You can see in the below figure how we have created a new master table called as "Standards" and linked the same using a simple foreign key.
Rule 5:- Watch for data separated by separators.
The second rule of 1st normal form says avoid repeating groups. One of the examples of repeating groups is explained in the below diagram. If you see the syllabus field closely, in one field we have too much data stuffed.These kinds of fields are termed as "Repeating groups". If we have to manipulate this data, the query would be complex and also I doubt performance of the queries.
The second rule of 1st normal form says avoid repeating groups. One of the examples of repeating groups is explained in the below diagram. If you see the syllabus field closely, in one field we have too much data stuffed.These kinds of fields are termed as "Repeating groups". If we have to manipulate this data, the query would be complex and also I doubt performance of the queries.
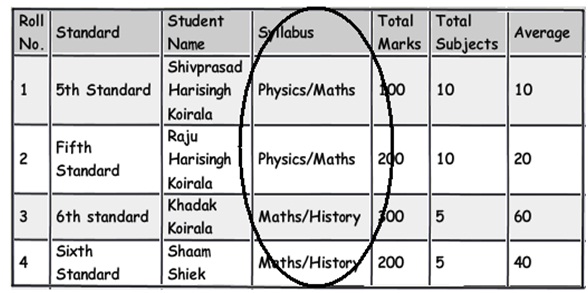
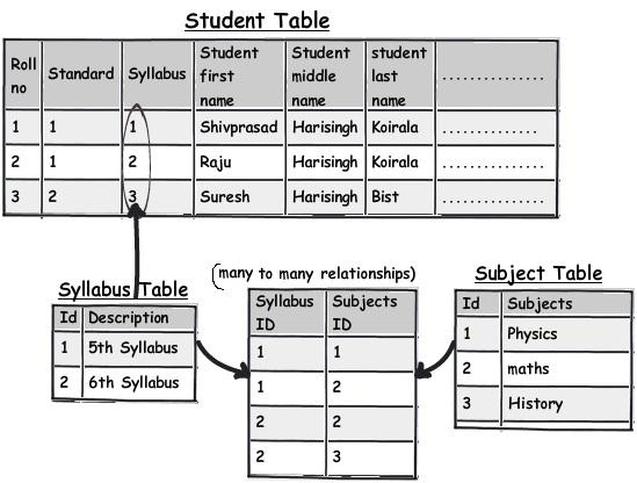
These kinds of columns which have data stuffed with separator's need special attention and a better approach would be to move that field to a different table and link the same with keys for better management.
So now let's apply the second rule of 1st normal form "Avoid repeating groups". You can see in the above figure I have created a separate syllabus table and then made a many-to-many relationship with the subject table.
With this approach the syllabus field in the main table is no more repeating and having data separators.
Rule 6:- Watch for partial dependencies.
With this approach the syllabus field in the main table is no more repeating and having data separators.
Rule 6:- Watch for partial dependencies.
